GPGPU 컴퓨팅의 개념에 대해서 설명하도록 하겠다.
더 심화된 내용은 GPU나 디바이스에 따라서 다르겠지만,
기본적인 전체적인 개념, 한번씩 머리에 담아두고 있으면 좋을 만한 개념을 설명하도록 하겠다.

GPU 컴퓨팅에 가장 중요한 개념 두가지는
1. 막강한 컴퓨팅 능력.
2. 엄청느린 메모리 접근
3. CPU-GPU와의 통신
이다.
1. 막강한 컴퓨팅 능력.
GPU는 기본적으로 간단한 프로세서가 수백 수 천개가 들어있다.
그렇기 때문에 GPU는 CPU에 비해 계산을 엄청 빠르게 할 수 있다.
그러나, GPU를 이용한 컴퓨팅은 GPU의 몇가지 특성 때문에 성능이 낮아 질 수 있다.
a. SIMT 모델 (branch divergence)
많은 코어를 갖고도 저전력, 소형화(?)를 위해서
GPU는 SIMT(singl instruction multiple threads)모델을 사용한다.
SIMT 모델의 단점은 한번에 하나의 instruction만 실행 가능 하다는 것으로,
if(a>0) b++;
else b--;
와 같은 코드에서 덧샘 한번, 다음 뺄셈 한번이 실행된다.
따라서 이런 분기문이 있을 때마다 2배의 실행 시간이 소요된다.
이런 분기를 줄이고 같은 warp에서는 같은 분기로 빠지게하는 최적화(optimization)가 꼭 필요하다.
2. 엄청느린 메모리 접근
이 부분 또한 GPU컴퓨팅의 성능에 큰 영향을 미친다. GPU가 global메모리(dram)에 접근하기 위해선 수백 cycle이 필요하다.
이 큰 지연(latency)를 숨기기(hiding) 위해 warp을 context switching 하는 기술을 사용한다.
또한, GPU메모리엔 hierarchy가 있으며,
cache또한 있다.
a. warp context switching
앞 서 말했듯이 큰 지연을 갖은 메모리 접근 명령어(instruction)을 실행할 때
그 수백 cycle을 기다리는것이 아니라 메모리 명령이 끝날때 까지 다른 warp을 가져와 다른 warp을 실행한다.
기본적으로 context switching을 위해선 register를 저장하고 바꾸는 기능이 필요하다.
그러나 GPU에선 많은 register를 가지고 있어 context switching 할때 overhead가 들지 않는다.
따라서 GPU는 context switching을 자유롭게 가능하다.
그렇기 위해선 warp을 최대한 넣어줘야하는데 그 warp의 수는
GPU마다 다르겠지만,
1) register의 수 ; 하나의 kernel이 사용하는 register수를 GPU(SM, streamming multiprocessor)가 갖고 있는 register의 수에 나눈 값 만큼 warp의 할당이 가능하다.
2) shared 메모리의 양 ; 이또한 하나의 kernel이 사용하는 shared memory의 양과 GPU의 메모리의 양에 따라 계산된다.
3) GPU가 갖을 수 있는 최대 warp의 수 ; 이건 GPU를 좋은걸 사용하는 수 밖에 없다.
이 세가지 요인에 의해 제한된다. 위 세가지를 모두 만족하는 최대의 숫자가 warp의 수가 된다.

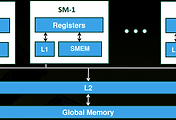
b. GPU 메모리 hierarchy
GPU엔 크게 다음과같은 메모리 hierarchy구조가 있다.
register - private memory - shared memory - global memory
왼쪽으로 갈 수록 thread하나만 사용가능한 메모리이며, 오른쪽으로 갈수록 모든 thread가 공유가능한 메모리이다.
또한, 왼쪽은 빠르고, 오른쪽으로 갈 수록 느리다.
thread간 공유 하는 메모리를 최소화 하여 최대한 왼쪽의 메모리를 사용하는게 좋다.
하지만, a에서 말했듯 최대한 많은 warp을 할당하기 위해 조절을 해주어야한다.

c. cache
GPU는 한번에 여러개의 데이터를 처리 하기 때문에 보통 한번에 많은 데이터를 가져온다.
예를 들어 warp의 크기가 32라면 보통 4Byte*32의 배수 만큼 한번에 가져 올 수 있다.
그러니깐 128Byte의 메모리를 가져오는게 100cycle이 걸린다면, 129Byte의 메모리를 가져오는데에는 200Cycle이 걸린다.
캐시를 잘 사용하기 위해선 메모리를 가져오는 양과 align을 조심 해야 한다.

3. CPU-GPU와의 통신.
CPU-GPU같의 데이터 전송은 PCI를 이용해 이루워지는데
이 또한 굉장히 느리다.
이 데이터 전송량을 최소화하고,
memory transfer overlapping이란 방법을 사용한 최적화가 필요하다.

'Program Language > OpenCL' 카테고리의 다른 글
| OpenCL 에러 (0) | 2013.01.21 |
|---|---|
| global memory replay overhead (0) | 2012.12.21 |
| [CUDA] occupancy (0) | 2012.11.07 |
| NVIDIA clEnqueueReadBuffer non-blocking bug(?) (0) | 2012.11.02 |
| Intel opencl platform analyzer (0) | 2012.10.15 |

댓글