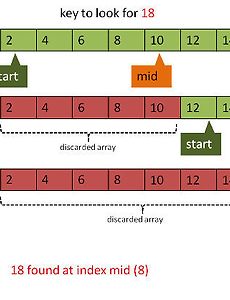
반응형 Program Language56 GPGPU Computing의 기본 개념. GPGPU 컴퓨팅의 개념에 대해서 설명하도록 하겠다. 더 심화된 내용은 GPU나 디바이스에 따라서 다르겠지만, 기본적인 전체적인 개념, 한번씩 머리에 담아두고 있으면 좋을 만한 개념을 설명하도록 하겠다. GPU 컴퓨팅에 가장 중요한 개념 두가지는 1. 막강한 컴퓨팅 능력. 2. 엄청느린 메모리 접근 3. CPU-GPU와의 통신 이다. 1. 막강한 컴퓨팅 능력. GPU는 기본적으로 간단한 프로세서가 수백 수 천개가 들어있다.그렇기 때문에 GPU는 CPU에 비해 계산을 엄청 빠르게 할 수 있다. 그러나, GPU를 이용한 컴퓨팅은 GPU의 몇가지 특성 때문에 성능이 낮아 질 수 있다. a. SIMT 모델 (branch divergence) 많은 코어를 갖고도 저전력, 소형화(?)를 위해서 GPU는 SIMT(s.. 2013. 4. 19. [C#] toString assembly function String foo(){return this.num.toString();} ldarg.0ldfld numcall toString()ret 이렇게 하면 될줄 알았는데 계속 죽는다. 이게 몰까?? ldfld num>> ldflda num 이렇게 했어야한다. 왜그럴까?? 2013. 2. 11. [코드이야기] 자바 JDK의 버그 Jon Bentley가 CMU에서 박사과정 학생들을 불러서 binary search 알고리즘을 써보라고 하였다. 당연히 binary search 알고리즘은 아주 기본적인 알고리즘이기 때문에 간단하게 구현할 수 있었을 것이다. 하지만, 모든 학생들의 코드에는 버그가 있었다. 그건, 무엇일까? 아래는 java.util.Arrays에 있는 실제 코드이다.1: public static int binarySearch(int[] a, int key) { 2: int low = 0; 3: int high = a.length - 1; 4: 5: while (low key) 12: high = mid - 1; 13: else 14: return mid; // key found 15: } 16: return -(low +.. 2013. 2. 7. OpenCL 에러 void boo(){if(get_local_id(2)!=0) return;foo();barrier(CLK_LOCAL_MEM_FENCE);} 작동 안한다.알아서 작동할 줄 알았는데.... void boo(){if(get_local_id(2)!=0) foo();barrier(CLK_LOCAL_MEM_FENCE);} 이렇게 하자. atomic 함수는 shared-reg에 써도 느리다. 왠만하면 피하자! branch divergence를 유발한다! 2013. 1. 21. 이전 1 2 3 4 ··· 14 다음