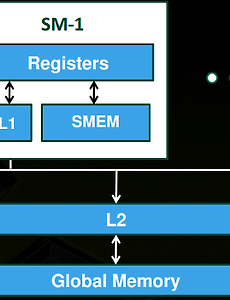
반응형 Program Language/OpenCL19 GPGPU Computing의 기본 개념. GPGPU 컴퓨팅의 개념에 대해서 설명하도록 하겠다. 더 심화된 내용은 GPU나 디바이스에 따라서 다르겠지만, 기본적인 전체적인 개념, 한번씩 머리에 담아두고 있으면 좋을 만한 개념을 설명하도록 하겠다. GPU 컴퓨팅에 가장 중요한 개념 두가지는 1. 막강한 컴퓨팅 능력. 2. 엄청느린 메모리 접근 3. CPU-GPU와의 통신 이다. 1. 막강한 컴퓨팅 능력. GPU는 기본적으로 간단한 프로세서가 수백 수 천개가 들어있다.그렇기 때문에 GPU는 CPU에 비해 계산을 엄청 빠르게 할 수 있다. 그러나, GPU를 이용한 컴퓨팅은 GPU의 몇가지 특성 때문에 성능이 낮아 질 수 있다. a. SIMT 모델 (branch divergence) 많은 코어를 갖고도 저전력, 소형화(?)를 위해서 GPU는 SIMT(s.. 2013. 4. 19. OpenCL 에러 void boo(){if(get_local_id(2)!=0) return;foo();barrier(CLK_LOCAL_MEM_FENCE);} 작동 안한다.알아서 작동할 줄 알았는데.... void boo(){if(get_local_id(2)!=0) foo();barrier(CLK_LOCAL_MEM_FENCE);} 이렇게 하자. atomic 함수는 shared-reg에 써도 느리다. 왠만하면 피하자! branch divergence를 유발한다! 2013. 1. 21. global memory replay overhead 쓸모없는 barrier를 제거 하였더니 global memory replay overhead가 줄었다.성능이 크게 올라갔다. //barrier(CLK_GLOBAL_MEM_FENCE);//mem_fence(CLK_GLOBAL_MEM_FENCE); 2012. 12. 21. [CUDA] occupancy 들어가는말, GPU는 캐시가 없거나 아주 작다. 따라서 Global 메모리를 접근 빈도수가 높은데, latency또한 높기 때문에 GPU의 계산 속도는 엄청나게 느릴 것이다. 이것을 보안하기 위한 방법이 메모리에 접근하는 동안 실행되는 warp을 교체(context switch)해버리는 방법을 사용하게 된다.또한, 앞뒤 instruction간의 dependency가 있을 경우도 stall을 해야하는데 이것 또한 빠른 context switch로 상쇄(hide)시킬 수 있다. (or ILP를 높임) Fermi의 경우,GMEM latency: 400-800 cyclesArithmetic latency: 18-22cycles GPU는 SM에서 context switch가 자유롭다. (overhead = 0)[.. 2012. 11. 7. 이전 1 2 3 4 5 다음